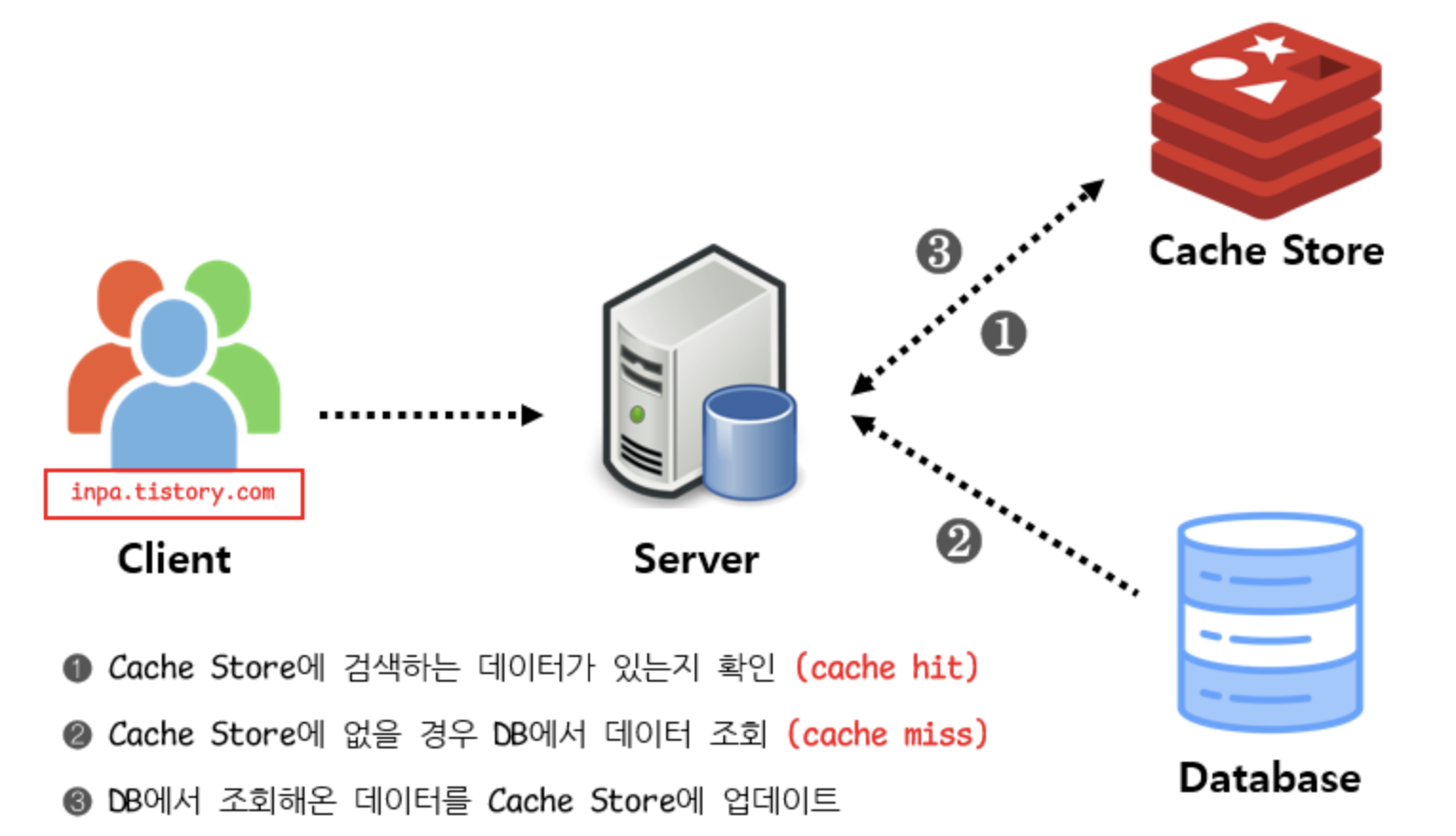
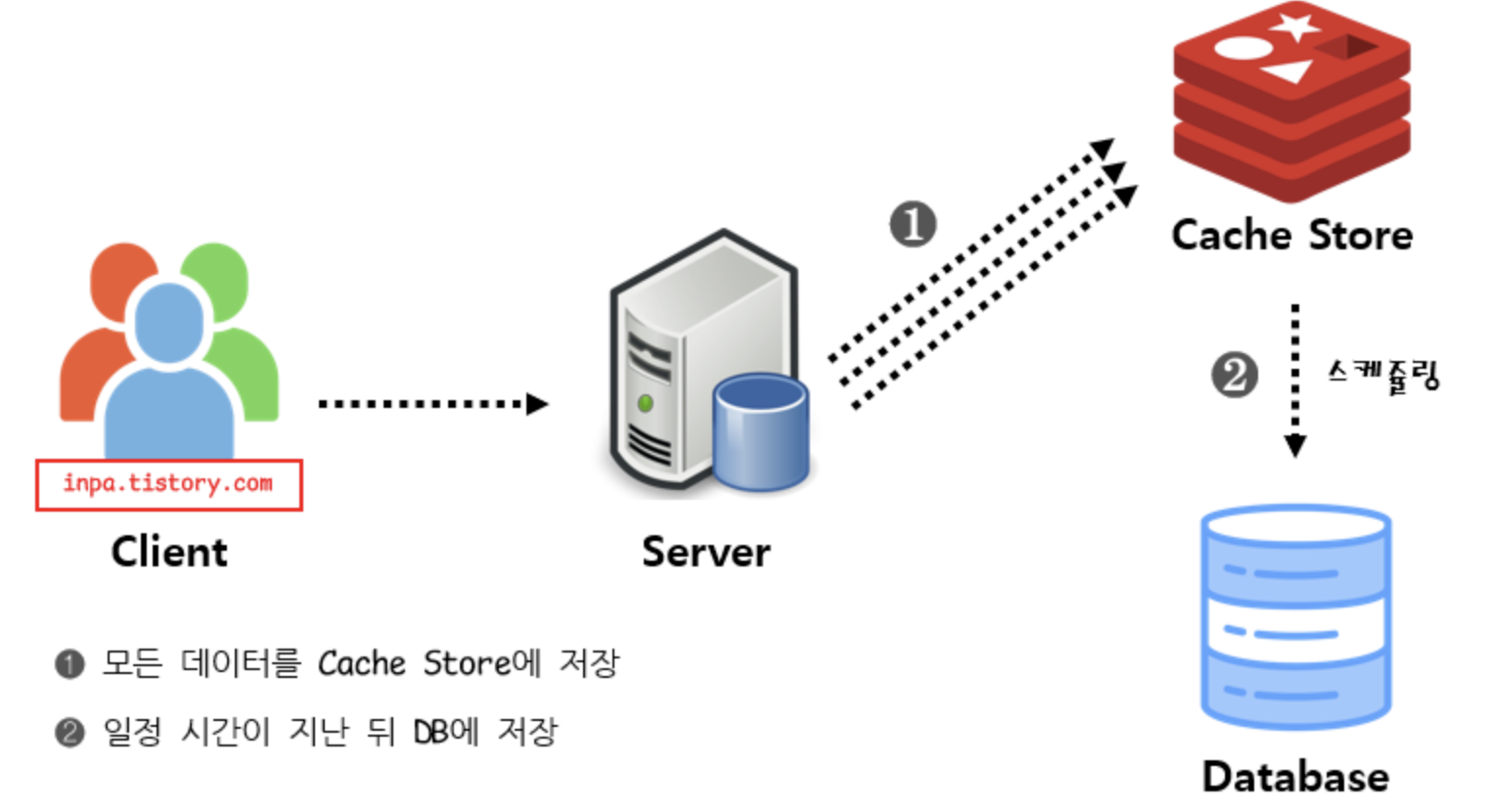
레디스를 이용한 데이터 캐싱 도입기 - Part1에 이어서 서비스에 레디스 캐시를 적용 후 진행한 성능 테스트에 대해 이야기해보려고 한다.
서론
개발자라면 누구나 DB만 사용했을 때 보다 캐싱을 적용한 로직이 처리가 빠르다는 것을 안다.
하지만 추상적으로 받아들이는 것 말고 구체적으로 검증을 하고 싶었다.
이전과 비교해서 서비스 로직이 성능적으로 얼마나 좋아졌는지 확인하기 위해서 테스트를 진행했다.
성능 테스트를 지원하는 도구는 여러 가지가 있지만 가장 익숙하고 간편한 nGrinder를 이용했다.
nGrinder
네이버에서 성능 측정을 목적으로 개발된 오픈소스 프로젝트이다. 이를 이용하면 서버의 부하를 테스트해서 성능을 측정할 수 있다.
nGrinder는 Controller와 Agent, 2가지 주요한 컴포넌트들로 이루어져 있다.
Controller는 성능테스트를 위한 웹 인터페이스를 제공한다. 테스트 프로세스들을 구성하고, 테스트 통계를 볼 수 있다.
그리고 테스트를 위한 스크립트를 생성하고 수정할 수 있도록 한다.
Agent는 타깃 서버에 부하를 주는 프로세스들과 스레드들을 동작시키는 역할을 한다.
그리고 타깃 시스템(서버)의 성능(CPU/Memory 등)을 모니터링할 수 있다.

이번 글에서는 nGrinder에 대한 자세한 내용은 생략하고자 한다.
좀 더 자세히 알고 싶다면 github의 userGuide 또는 다른 블로그들을 참조하는 것을 추천한다.
테스트
이제 테스트를 진행할 시간이다.
우선 시나리오는 두 개다.
1. 기존 로직에 대한 테스트 (DB)
2. 새로운 로직에 대한 테스트(Redis + DB)
테스트 설정은 다음과 같이 하였다.
Target 서버: Local 환경, 개발서버
Vuser(virtural user로 동시에 접속하는 유저수를 의미) : 500명
테스트 시간: 10분
테스트 진행 시 겪은 시행착오
테스트를 진행했는데 생각보다 결과에서 차이가 없었다. 문제의 원인을 찾다가 redis를 잘못 적용했나 생각하며 꽤 오랜 시간 삽질을 했었다. 약간 창피하지만 혹시나 나와 같은 실수를 하는 사람을 위해 확인한 내용을 공유해 본다.
첫 번째는 테스트 데이터의 양이였다. API가 수행되는데 조회할 데이터 자체가 작다 보니 캐시 적용효과를 테스트에서 확인하기 어려웠다. 그래서 운영환경과 비슷하게 많은 데이터를 모집단으로 설정하는 게 필요하다 판단했고 테스트 관련 데이터는 운영환경에서 가져와서 처리했다.
두 번째는 API 로직 이해 부족이었다. 첫 번째 원인을 수정하였는데도 두 가지 테스트에서 차이가 눈에 띌정도로 보이지 않았다. 확인해 보니 해당 API는 페이징 처리를 해두었는데 request에 paging 관련 값은 default 던지고 있었다. 그래서 계속 같은 데이터만 return 하는 구조였다. 이 원인은 테스트 스크립트의 api 호출 부분을 수정해서 처리하였다.
테스트환경, 데이터, 로직에 대한 정확한 이해를 기반으로
테스트를 진행해야겠다는 점을 다시 한번 느꼈던 상황들이었다. 😭😭
테스트 스크립트는 기본 template을 약간 수정해서 작성했다. 전체 코드는 아래 더보기로 확인하길 바란다.
- Redis Test Script
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import org.ngrinder.http.cookie.Cookie
import org.ngrinder.http.cookie.CookieManager
/**
* A simple example using the HTTP plugin that shows the retrieval of a single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author admin
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static Map<String, String> headers = ["x-balcony-id":"BOMTOON_COM"]
public static Map<String, Object> params = ["groupMenu":"SCHEDULE_ALL","isIncludeAdult":"true","contentsThumbnailType":"MAIN","isIncludeTen":"false","isIncludeTenComplete":"false","sort":"POPULAR"]
public static List<Cookie> cookies = []
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test = new GTest(1, "http://localhost:8080")
request = new HTTPRequest()
grinder.logger.info("before process.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("before thread.")
}
@Before
public void before() {
headers.put("Authorization", "Bearer eyJhbGciOiJIUzI1NiJ9.eyJlbWFpbCI6Im1DbnNLTWhGNFZiMGJZK0g0amlwNWVSNHF4QTJwaHhQaDA3SlNwTm1Oc1pCZXJGS2Vkcmpidm05aVY2RzVkZkgiLCJzbnNQcm92aWRlciI6IkgxK3RUdU9EQ1lBQ3ZFKzdwNGJNR1E9PSIsImlzQWR1bHQiOiJjYUZmRU00Z0VIUmZXd215VDNCMXlnPT0iLCJ1c2VySWQiOiJYR3k1c1ByQmxFWmxpZXVNenp2cDZBPT0iLCJ1dWlkIjoiUERnelE3NVR5S3UzQWhpb2gzQTZtRHBheDhmQk10cUdnT3ZOL3hBa0VRVGN3V1QxQ1MyQVk3bmx6WWNtQ3dMQSIsImlhdCI6MTY3OTk2ODEzMywiZXhwIjoxNjgwMDU0NTMzfQ.ezMtHPpfpXEeQlF0aYxfyC8dZFgPGMfYMaeQkT6pl6Q")
request.setHeaders(headers)
CookieManager.addCookies(cookies)
grinder.logger.info("before. init headers and cookies")
}
@Test
public void test() {
int page = (int)(Math.random()*500)
params.put("page", Integer.toString(page))
HTTPResponse response = request.GET("http://localhost:8080/v2/contents/group/new", params)
if (response.statusCode == 301 || response.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", response.statusCode)
} else {
assertThat(response.statusCode, is(200))
}
}
}- DB Test Script
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import org.ngrinder.http.cookie.Cookie
import org.ngrinder.http.cookie.CookieManager
/**
* A simple example using the HTTP plugin that shows the retrieval of a single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author admin
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static Map<String, String> headers = ["x-balcony-id":"BOMTOON_COM"]
public static Map<String, Object> params = ["groupMenu":"SCHEDULE_ALL","isIncludeAdult":"true","contentsThumbnailType":"MAIN","isIncludeTen":"false","sort":"POPULAR"]
public static List<Cookie> cookies = []
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test = new GTest(1, "http://localhost:8080")
request = new HTTPRequest()
grinder.logger.info("before process.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("before thread.")
}
@Before
public void before() {
headers.put("Authorization", "Bearer eyJhbGciOiJIUzI1NiJ9.eyJlbWFpbCI6Im1DbnNLTWhGNFZiMGJZK0g0amlwNWVSNHF4QTJwaHhQaDA3SlNwTm1Oc1pCZXJGS2Vkcmpidm05aVY2RzVkZkgiLCJzbnNQcm92aWRlciI6IkgxK3RUdU9EQ1lBQ3ZFKzdwNGJNR1E9PSIsImlzQWR1bHQiOiJjYUZmRU00Z0VIUmZXd215VDNCMXlnPT0iLCJ1c2VySWQiOiJYR3k1c1ByQmxFWmxpZXVNenp2cDZBPT0iLCJ1dWlkIjoiUERnelE3NVR5S3UzQWhpb2gzQTZtRHBheDhmQk10cUdnT3ZOL3hBa0VRVGN3V1QxQ1MyQVk3bmx6WWNtQ3dMQSIsImlhdCI6MTY3OTk2ODEzMywiZXhwIjoxNjgwMDU0NTMzfQ.ezMtHPpfpXEeQlF0aYxfyC8dZFgPGMfYMaeQkT6pl6Q")
request.setHeaders(headers)
CookieManager.addCookies(cookies)
grinder.logger.info("before. init headers and cookies")
}
@Test
public void test() {
int page = (int)(Math.random()*500)
params.put("page", Integer.toString(page))
HTTPResponse response = request.GET("http://localhost:8080/v2/contents/group", params)
if (response.statusCode == 301 || response.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", response.statusCode)
} else {
assertThat(response.statusCode, is(200))
}
}
}테스트 결과
테스트 결과는 다음과 같았다.
- DB Test 결과
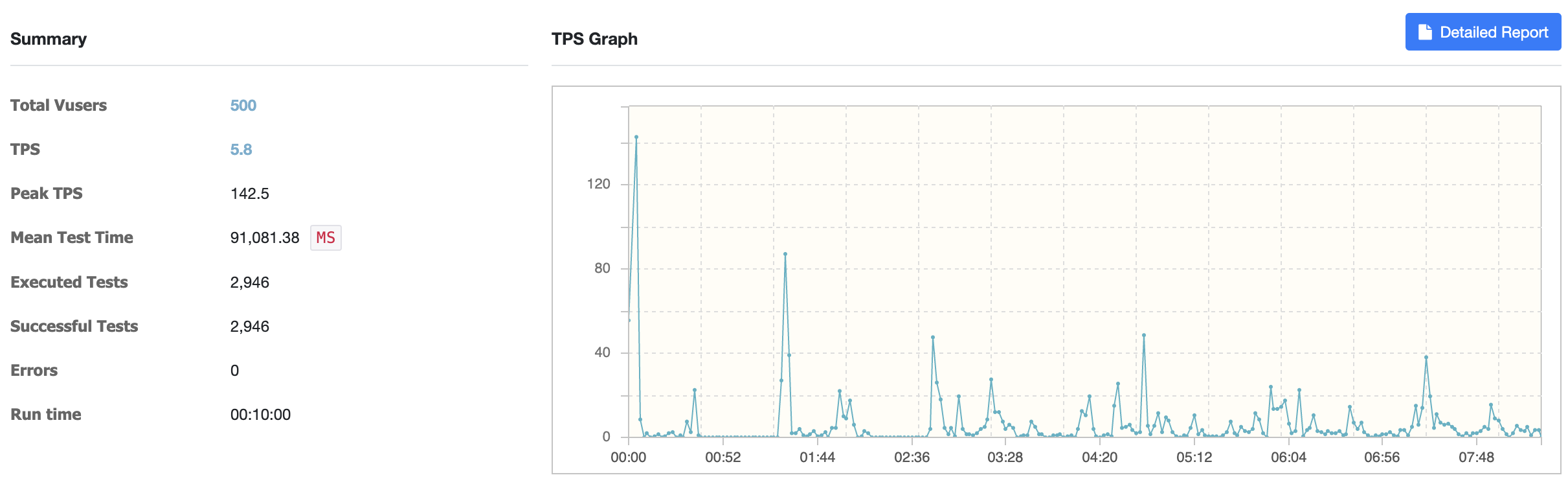
- Redis Test 결과

TPS와 테스트시간만 체크했다.
TPS는 초당 트랜잭션 완료수이다. 높을수록 성능이 높다는 것을 의미한다.
테스트 시간은 user가 request 한 시점에서 시스템이 response 한 시점, 즉 API 수행시간이다.
두 개의 결과에 대한 차이는 10배 이상 난 것을 확인할 수 있었다.
결론
DB만 사용할 때보다 캐싱을 도입했을 때 성능적인 차이를 구체적인 수치로 확인할 수 있어서 좋았다.
나와 같은 멍청한 실수를 하지 않으려면 몇 가지만 신경 쓰고 테스트를 진행하길 바란다.
구현한 로직 프로세스, 모집단의 데이터의 양, 서버 성능에 따라서 테스트의 결과는 확연하게 달라질 수 있다는 점을 인지하는 게 중요할것 같다.
'MyStory > dev_life' 카테고리의 다른 글
| Chat GPT는 업무에 얼마나 도움이 될까? (0) | 2023.04.28 |
|---|---|
| 코딩 스타일 컨벤션 그거 중요해? 응 중요해!!! (0) | 2023.04.17 |
| 레디스를 이용한 데이터 캐싱 도입기 - Part1 (0) | 2023.03.20 |
| 갑자기 헷갈린 git 명령어 pull, merge (1) | 2023.03.04 |
| 개발자 퍼스널 브랜딩 과정 후기 :Know yourself (0) | 2023.02.22 |